随着社交媒体平台的迅速发展,微博等平台已成为信息传播的重要渠道。海量的微博数据也带来了信息管理、内容监控和安全分析等方面的挑战。本文旨在探讨基于爬虫技术的网络空间微博信息管理系统的设计与实现,结合网络与信息安全软件开发的理论与实践,提供一个完整的计算机毕业设计解决方案。
一、系统需求分析
微博信息管理系统的主要目标是从微博平台采集数据,进行高效存储、分析和可视化,同时确保信息安全。系统需求包括:
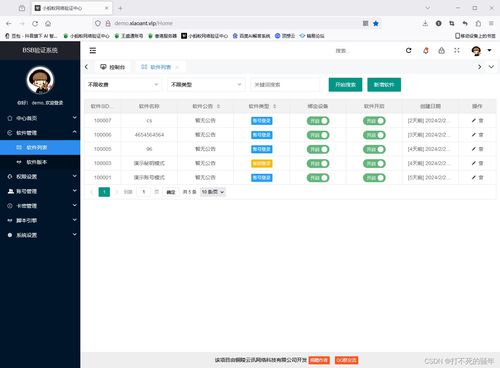
- 数据采集模块:利用网络爬虫技术,自动化抓取微博内容,包括用户信息、博文、评论和转发数据。
- 数据存储模块:设计数据库结构,支持大规模数据的存储和快速检索,采用关系型数据库(如MySQL)和NoSQL数据库(如MongoDB)相结合的方式。
- 信息管理模块:实现数据清洗、去重、分类和情感分析功能,帮助用户监控舆情和识别潜在风险。
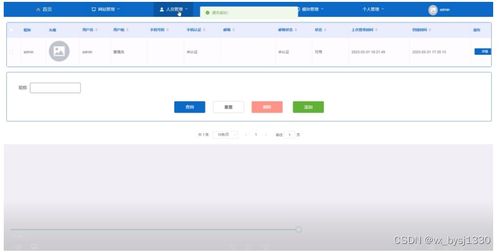
- 安全与权限管理:集成网络安全机制,如数据加密、访问控制和防爬虫反制策略,确保系统运行的合法性和数据隐私。
- 可视化界面:提供用户友好的Web界面,展示数据统计结果和实时监控信息。
二、系统设计与实现
系统采用分层架构,包括数据层、业务逻辑层和表示层。关键技术点如下:
- 爬虫模块实现:使用Python的Scrapy或Requests库构建多线程爬虫,模拟用户行为以绕过平台限制。通过API接口或HTML解析获取数据,并设置合理的爬取频率以避免IP封禁。
- 数据处理与存储:对采集的原始数据进行预处理,包括去除噪声、格式统一和关键词提取。数据库设计采用ER模型,确保数据一致性和可扩展性。
- 信息安全机制:在数据采集和传输过程中应用HTTPS协议,对敏感信息进行加密存储。引入用户认证和角色权限系统,防止未授权访问。
- 开发工具与环境:使用Java或Python作为后端开发语言,结合Spring Boot或Django框架;前端采用HTML/CSS/JavaScript和Vue.js;部署在云服务器上,实现高可用性。
三、应用与展望
该系统可广泛应用于政府舆情监控、企业品牌管理和学术研究中。可集成机器学习算法以提升情感分析和异常检测的准确性,并扩展至多平台数据采集,以增强系统的通用性。通过本设计,开发者可以掌握网络爬虫、数据库管理和信息安全等核心技能,为网络与信息安全领域贡献实用工具。
基于爬虫的微博信息管理系统不仅能够高效处理海量数据,还能在网络安全框架下提供可靠的信息管理方案。本毕业设计源码85633为相关开发提供了参考,强调了在数据驱动的时代中,平衡效率与安全的重要性。